
Paper Form Ocr Data
Paper Form Ocr Data - Our blog will discuss in depth how it works, its benefits, and how it can help your workflow. Extract the actual text content from each element, 3. Astera reportminer is a powerful tool that enables you to capture, transform, and convert data from any form or document format. Machine learning productsfree tier detailssign up for freecreate a free account Ocr software uses a scanner to reprocess the physical form of a document to editable, digital text. Classify the elements, using their. Organizations design and publish pdf fillable forms that can be completed digitally, then use ocr to extract data from the printed forms when they’re returned.
The data can then be used to streamline operations, automate procedures and boost efficiency. The read ocr model extracts print and handwritten style text as lines and words. As an essential part of rag, external knowledge bases are commonly built. Detect the text elements (printed or handwritten) on the form and calculate their expected sizes and positions, 2.
The model outputs bounding polygon coordinates and confidence for the extracted words. From there, we’ll review the steps required to implement a document ocr pipeline. As ocr only recognizes characters from sources, data extraction does more than that. Previous approaches for scene text detection have already achieved promising performances across various benchmarks. Detect the text elements (printed or handwritten) on the form and calculate their expected sizes and positions, 2. Our blog will discuss in depth how it works, its benefits, and how it can help your workflow.
OCR Full Form Optical Character Recognition

Existing benchmarks are often limited by narrow scenarios and specified tasks. The styles collection includes any handwritten style for lines if detected along with the spans. Previous approaches for scene text detection have already achieved.
Create a Form using OCR
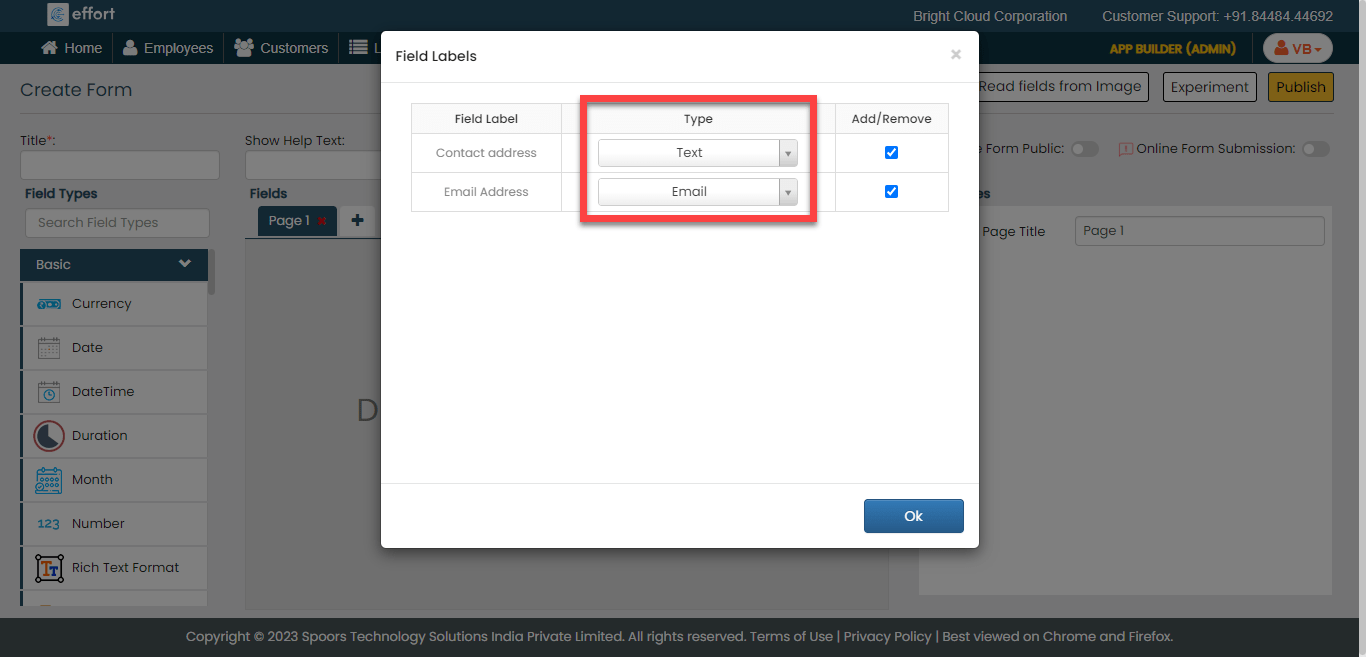
Astera reportminer is a powerful tool that enables you to capture, transform, and convert data from any form or document format. Grooper is an intelligent document processing and digital data integration solution that empowers organizations.
OCR Sheet / ICR Sheet Printing Service in Mumbai

Forms) into structured data (e.g. In the first part of this tutorial, we’ll briefly discuss why we may want to ocr documents, forms, invoices, or any type of physical document. There should be 3 main.
Data Mining OCR PDFs Getting Things Straight WZB Data Science Blog

Machine learning productsfree tier detailssign up for freecreate a free account The data can then be used to streamline operations, automate procedures and boost efficiency. Detect the text elements (printed or handwritten) on the form.
OCR Software Reduce Manual Data Entry, Convert Documents to Text
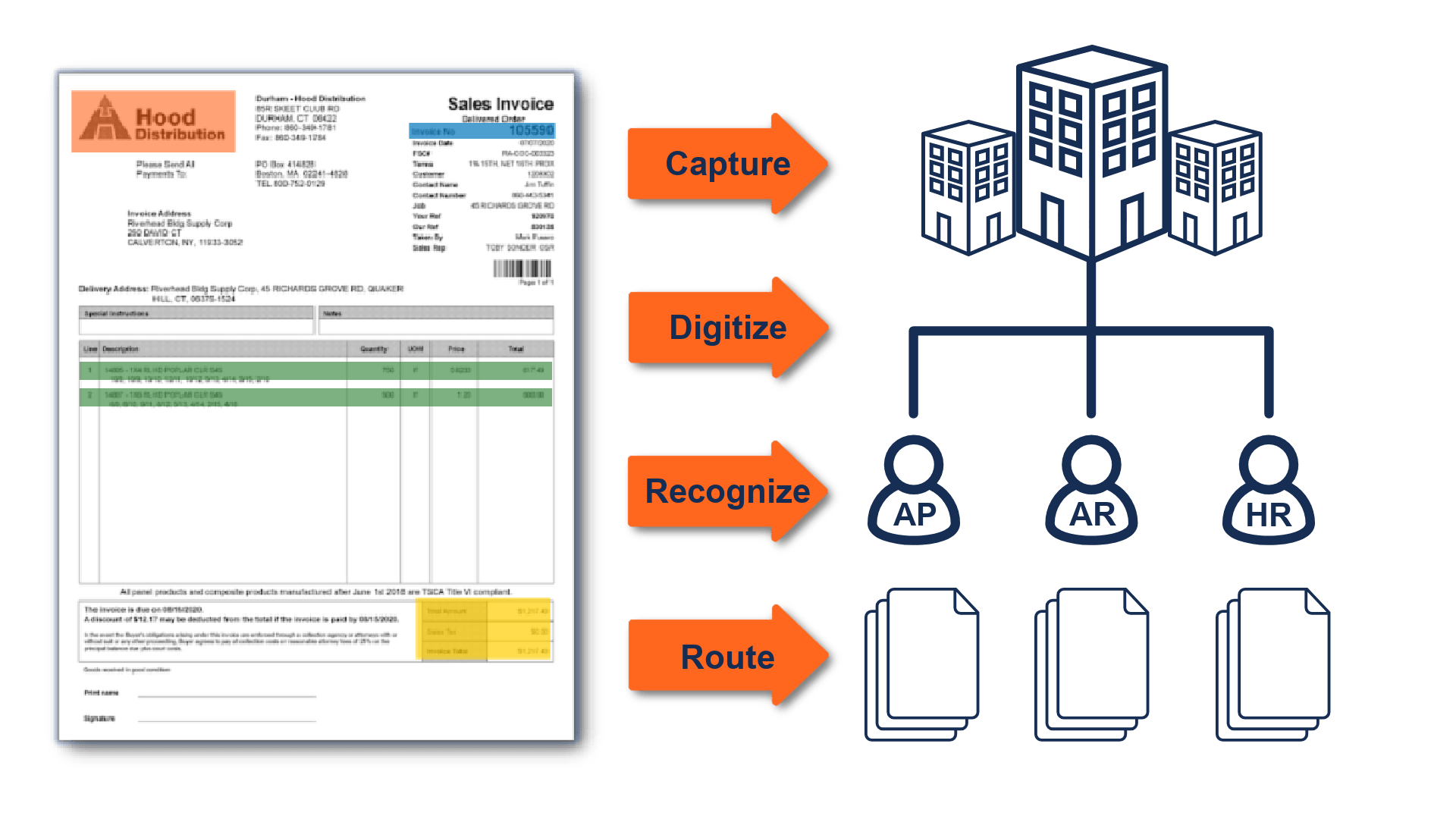
As an essential part of rag, external knowledge bases are commonly built. Organizations design and publish pdf fillable forms that can be completed digitally, then use ocr to extract data from the printed forms when.
How Can You Use OCR Data? Rossum.ai

Businesses heavily rely on ocr and data extraction because it gives them a method to access data that is kept in a variety of forms. The styles collection includes any handwritten style for lines if.
GitHub HarendraKumarSingh/formextractorocr Template based form

In the first part of this tutorial, we’ll briefly discuss why we may want to ocr documents, forms, invoices, or any type of physical document. As ocr only recognizes characters from sources, data extraction does.
What is the significance of OCR for financial document processing?

The data can then be used to streamline operations, automate procedures and boost efficiency. Machine learning productsfree tier detailssign up for freecreate a free account Extract the actual text content from each element, 3. The.
From there, we’ll review the steps required to implement a document ocr pipeline. Forms) into structured data (e.g. Previous approaches for scene text detection have already achieved promising performances across various benchmarks. Existing benchmarks are often limited by narrow scenarios and specified tasks. Our blog will discuss in depth how it works, its benefits, and how it can help your workflow.
The styles collection includes any handwritten style for lines if detected along with the spans. Previous approaches for scene text detection have already achieved promising performances across various benchmarks. The read ocr model extracts print and handwritten style text as lines and words. As ocr only recognizes characters from sources, data extraction does more than that.
Organizations Design And Publish Pdf Fillable Forms That Can Be Completed Digitally, Then Use Ocr To Extract Data From The Printed Forms When They’re Returned.
Ocr data extraction is a technology that transforms scanned documents into usable digital data. Previous approaches for scene text detection have already achieved promising performances across various benchmarks. In the first part of this tutorial, we’ll briefly discuss why we may want to ocr documents, forms, invoices, or any type of physical document. As ocr only recognizes characters from sources, data extraction does more than that.
The Read Ocr Model Extracts Print And Handwritten Style Text As Lines And Words.
Extract the actual text content from each element, 3. It can handle both structured and unstructured documents, adapt to various layouts, and continuously improve its performance. As an essential part of rag, external knowledge bases are commonly built. Grooper is an intelligent document processing and digital data integration solution that empowers organizations to extract meaningful information from paper/electronic documents and other forms of unstructured data.
Ocr Software Uses A Scanner To Reprocess The Physical Form Of A Document To Editable, Digital Text.
Detect the text elements (printed or handwritten) on the form and calculate their expected sizes and positions, 2. Classify the elements, using their. Machine learning productsfree tier detailssign up for freecreate a free account The styles collection includes any handwritten style for lines if detected along with the spans.
Forms) Into Structured Data (E.g.
From there, we’ll review the steps required to implement a document ocr pipeline. Existing benchmarks are often limited by narrow scenarios and specified tasks. Idp combines ocr, ai, and ml to automate form processing, making data extraction faster and more accurate than traditional methods. There should be 3 main stages in predicting the contents of a form using the supervised learning approach, 1.
Ocr data extraction is a technology that transforms scanned documents into usable digital data. Businesses heavily rely on ocr and data extraction because it gives them a method to access data that is kept in a variety of forms. As an essential part of rag, external knowledge bases are commonly built. The styles collection includes any handwritten style for lines if detected along with the spans. In the first part of this tutorial, we’ll briefly discuss why we may want to ocr documents, forms, invoices, or any type of physical document.